Building Worlds for Reinforcement Learning
24 Jan 2017OpenAI’s Gym places reinforcement learning into the masses. It comes with a wealth of environments from the classic cart pole, board games, Atari, and now the new Universe which adds flash games and PC Games like GTA or Portal. This is great news, but for someone starting out, working on some of these games is overkill. You can learn a lot more in a shorter time, by playing around with some smaller toy environments.
One area I like within the gym environments are the classic control problems (besides the fun of eating melon and poop). These are great problems for understanding the basics of reinforcement learning because we intutiively understand the rewards and they run really fast. Its not like pong that can take several days to train, instead, you can train these environments within minutes!
If you aren’t happy with the current environments, it is possible to modify and even add more environments. In this post, I will highlight other environments and share how I modified an Acrobot-v1 environment.
RLPy
To begin, grab the repo for the OpenAI gym. Inside the repo, navigate to gym/envs/classic_controlwhere you will see the scripts that define the class control environments. If you open one of the scripts, you will see a heading on the top that says:
__copyright__ = "Copyright 2013, RLPy http://acl.mit.edu/RLPy"
Ahh! In the spirit of open source, OpenAI stands on the shoulders of another reinforcement library, RLPy. You can learn a lot more about them at the RLPy site or take a look at their github. If you browse here, you can find the original script that was used in OpenAI under rlpy /rlpy/Domains. The interesting thing here is that there are a ton more interesting reinforcement problems!
You can run these using RLPy or you can try and hack this into OpenAI.
Modifying OpenAI Environments
I decided to modify the Acrobot environment. Acrobot is a 2-link pendulum with only the second joint actuated (it has three states, left, right, and no movement). The goal is to swing the end to a height of at least one link above the base. If you look at the leaderboard on OpenAIs site, they meet that criterion, but its not very impressive. Here is the current highest scoring entry:
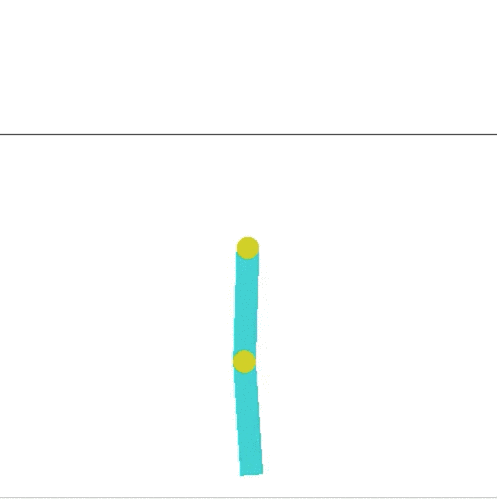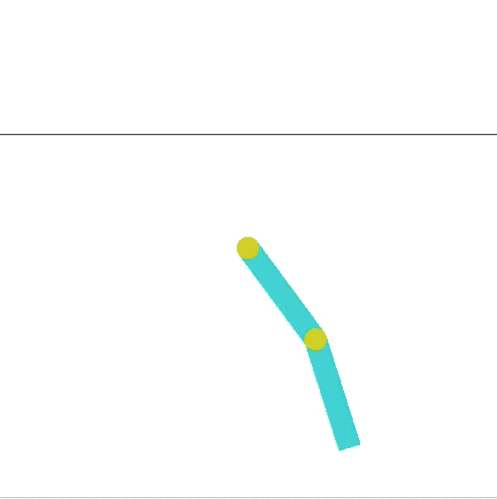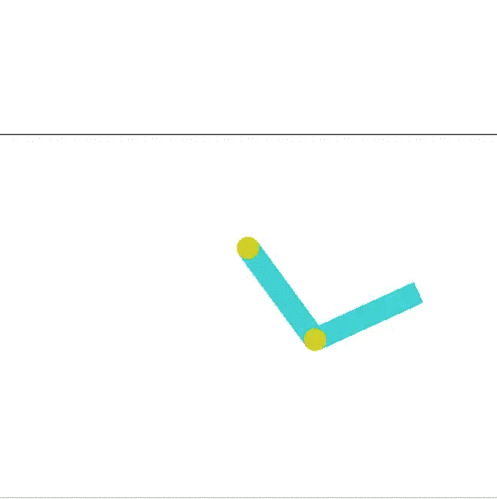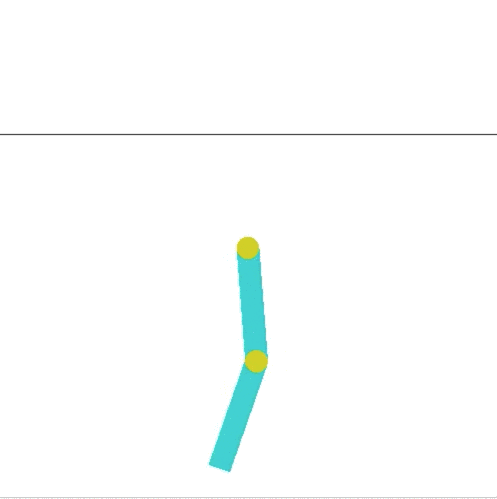
This is way boring compared to what Hardmaru shows in his demo, where a pendulum is capable of balancing for a short time.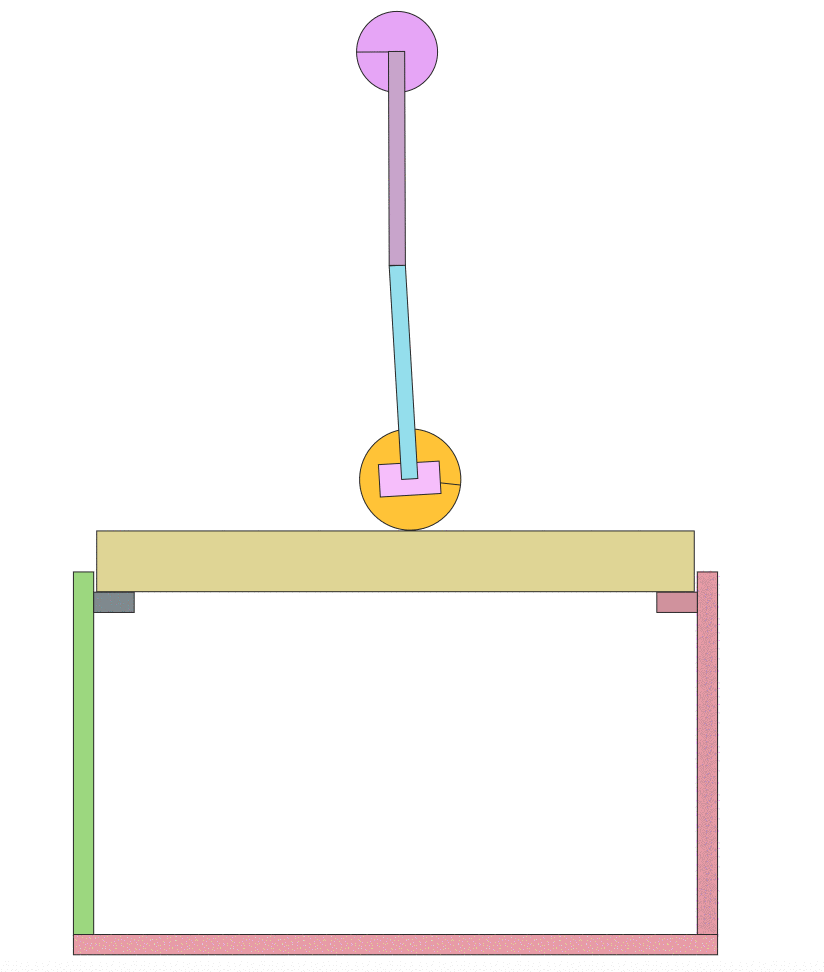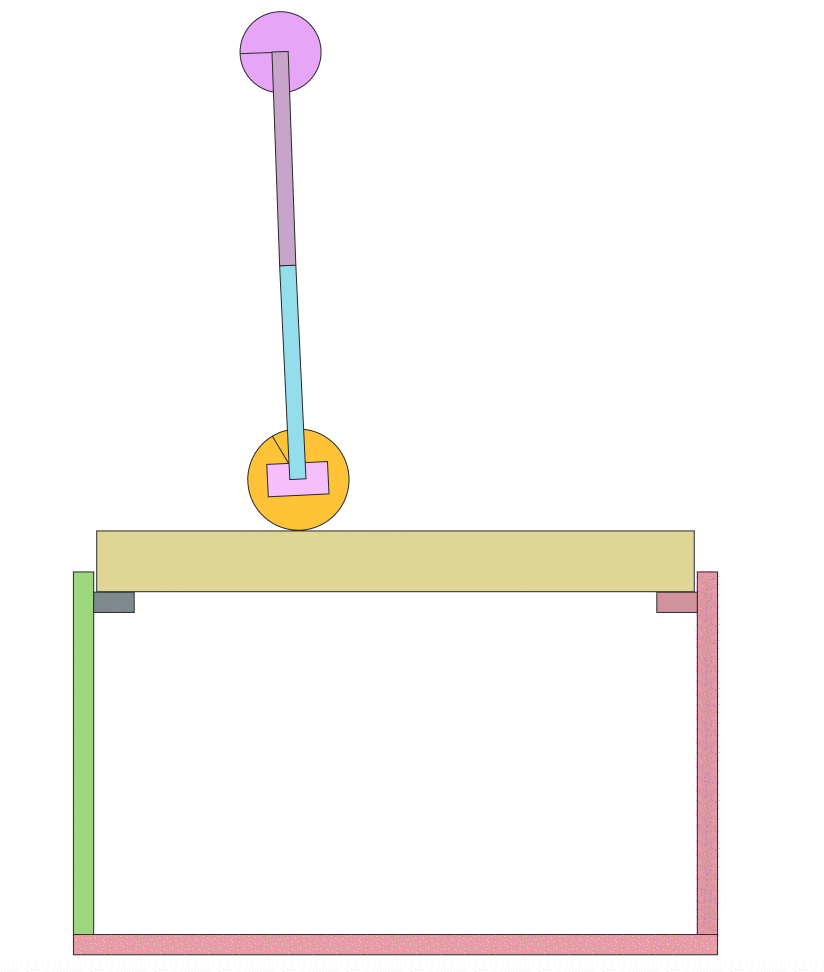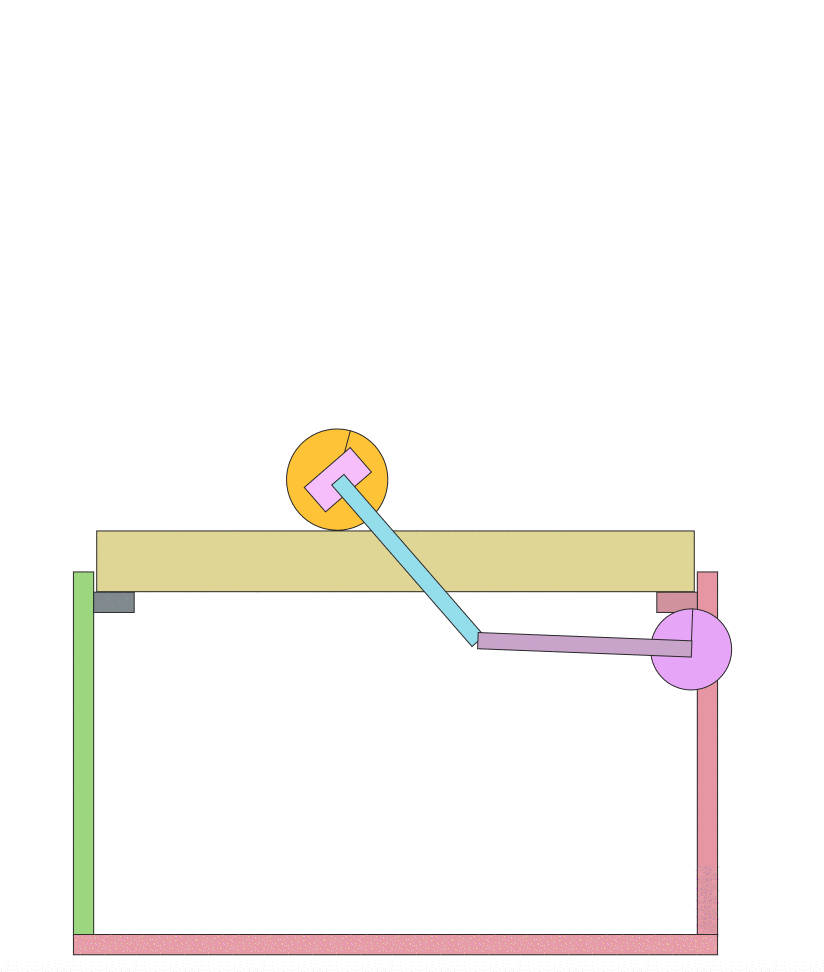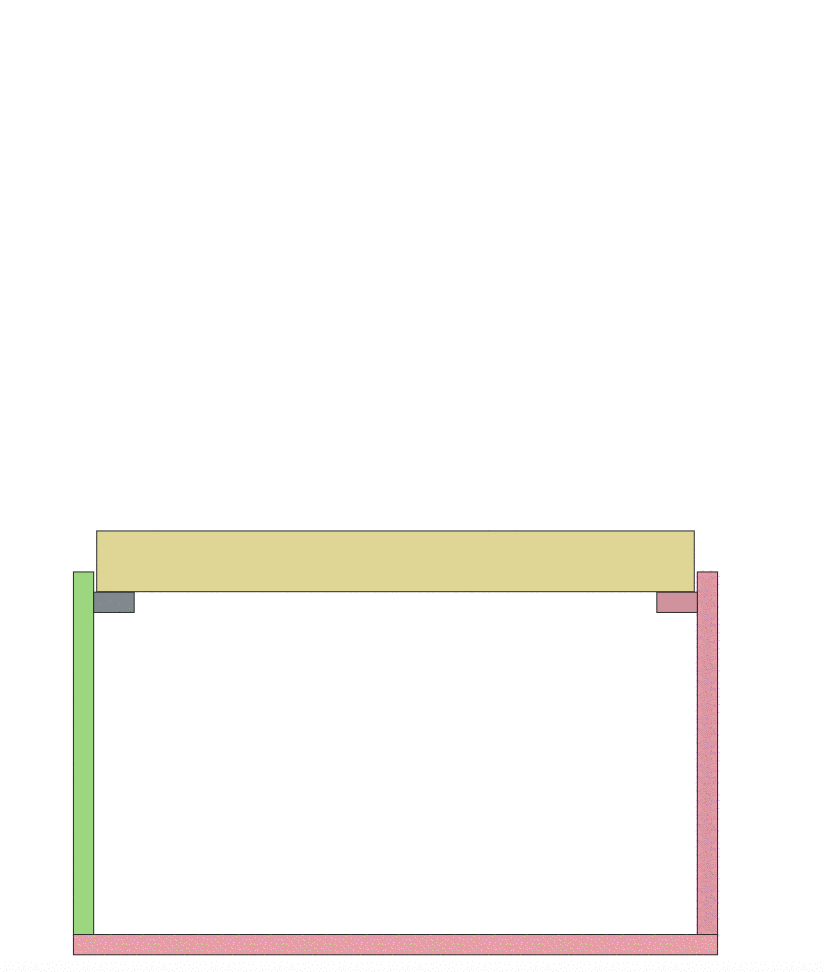
So I decided to try and modify the Acrobot demo to make this task a little more interesting, Acrobot gist here. The main change was to the reward system. I added a variable steps_beyond_done that would keep track of successes when the end was swung high. I also changed the reward structure, so it would gradually be rewarded as it swung higher. I also changed g to 0, this removes gravity’s effect.
self.rewardx = (-np.cos(s[0]) - np.cos(s[1] + s[0])) ##Swung height is calculated
if self.rewardx < .5:
reward = -1.
self.steps_beyond_done = 0
if (self.rewardx > .5 and self.rewardx < .8):
reward = -0.8
self.steps_beyond_done = 0
if self.rewardx > .8:
reward = -0.6
if self.rewardx > 1:
reward = -0.4
self.steps_beyond_done += 1
if self.steps_beyond_done > 4:
reward = -0.2
if self.steps_beyond_done > 8:
reward = -0.1
if self.steps_beyond_done > 12:
reward = 0.
Another important file to be aware of is where the benchmarks are kept for each environment. You can navigate to this at gym/gym/benchmarks/__init__.pyWithin this file, you will see the following:
{'env_id': 'Acrobot-v1',
'trials': 3,
'max_timesteps': 100000,
'reward_floor': -500.0,
'reward_ceiling': 0.0,
},
I then ran an implementation of Asynchronous Advantage Actor Critic A3C) by Arno Moonens. After running for a half hour, you can see the improvement in the algorithm:

Now a half hour later:
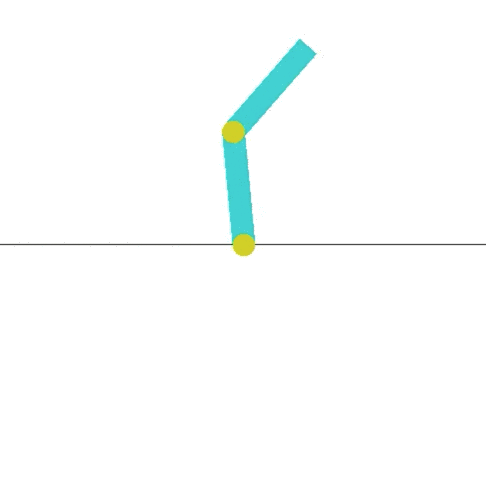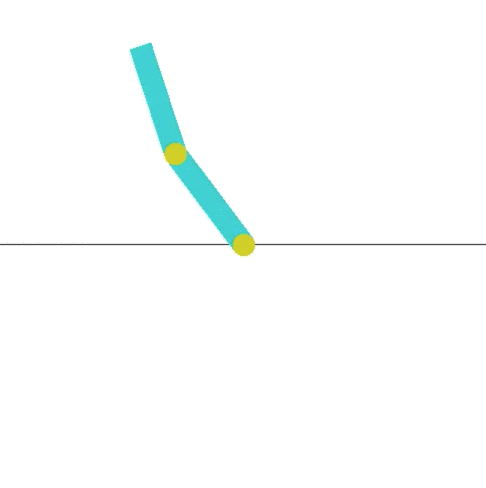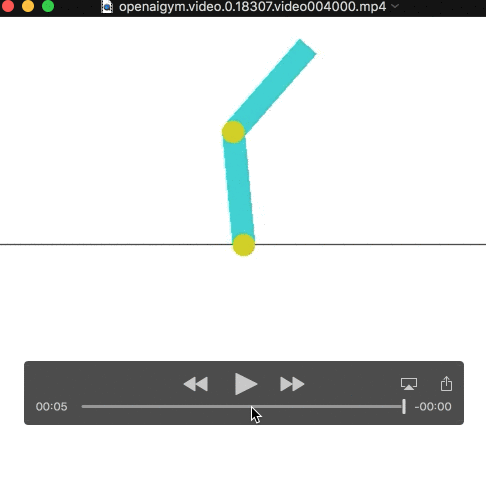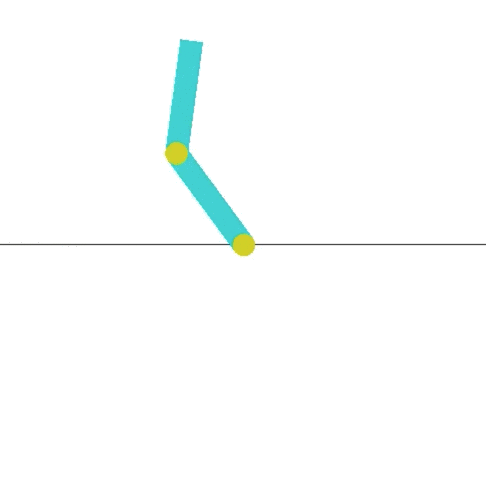
The result is teaching the pendulum to stay up for an extended time! This is much more interesting and what I was looking for. I hope this will inspire others to build new and interesting environments.