Introduction
Data scientists often do not have large amounts of labeled data. This issue is even graver when dealing with problems with tens or hundreds of classes. The reality is very few text classification problems get to the point where adding more labeled data isn’t improving performance.
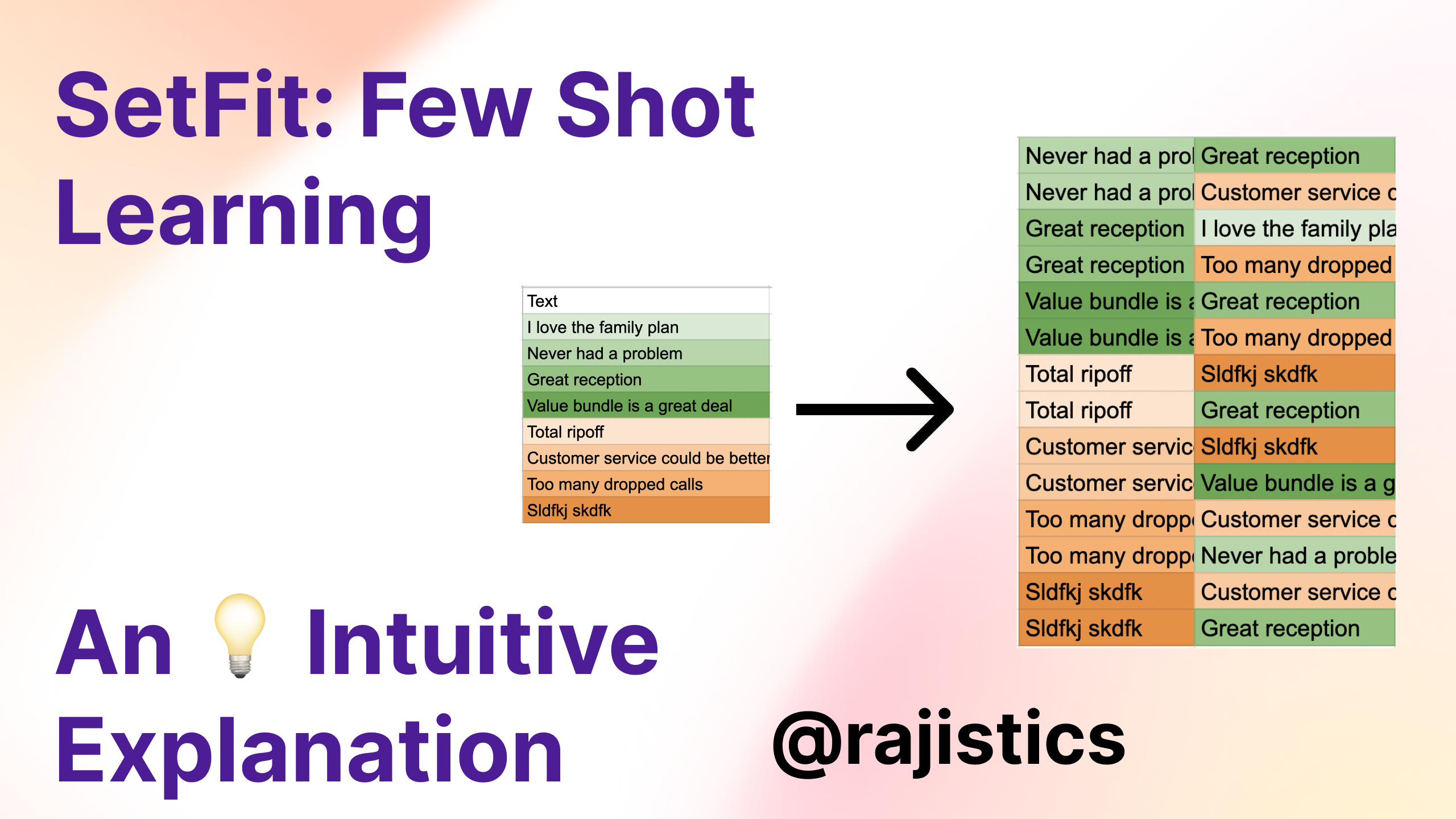
SetFit offers a few-shot learning approach for text classification. The paper’s results show across many datasets, it’s possible to get better performance with less labeled data. This technique uses contrastive learning to build a larger dataset for fine-tuning a text classification model. This approach was new to me and was why I did a video explaining how contrastive learning helps with text classification.
I have created a Colab 📓 companion notebook at https://bit.ly/raj_setfit, and the Youtube 🎥 video that provides a detailed explanation. I walk through a simple churn example to give the intuition behind SetFit. The notebook trains the CR (customer review dataset) highlighted in the SetFit paper.
The SetFit github contains the code, and a great deep dive for text classification is found on Philipp’s blog. For those looking to productionize a SetFit model, Philipp has also documented how to create the Hugging Face endpoint for a SetFit model.
So grab your favorite text classification dataset and give it a try!