Introduction
I was wowed by ChatGPT. While I understood tasks like text generation and summarization, something was different with ChatGPT. When I looked at the literature, I saw this work exploring reasoning. Models reasoning, c’mon. As a very skeptical data scientist, that seemed far-fetched to me. But I had to explore.
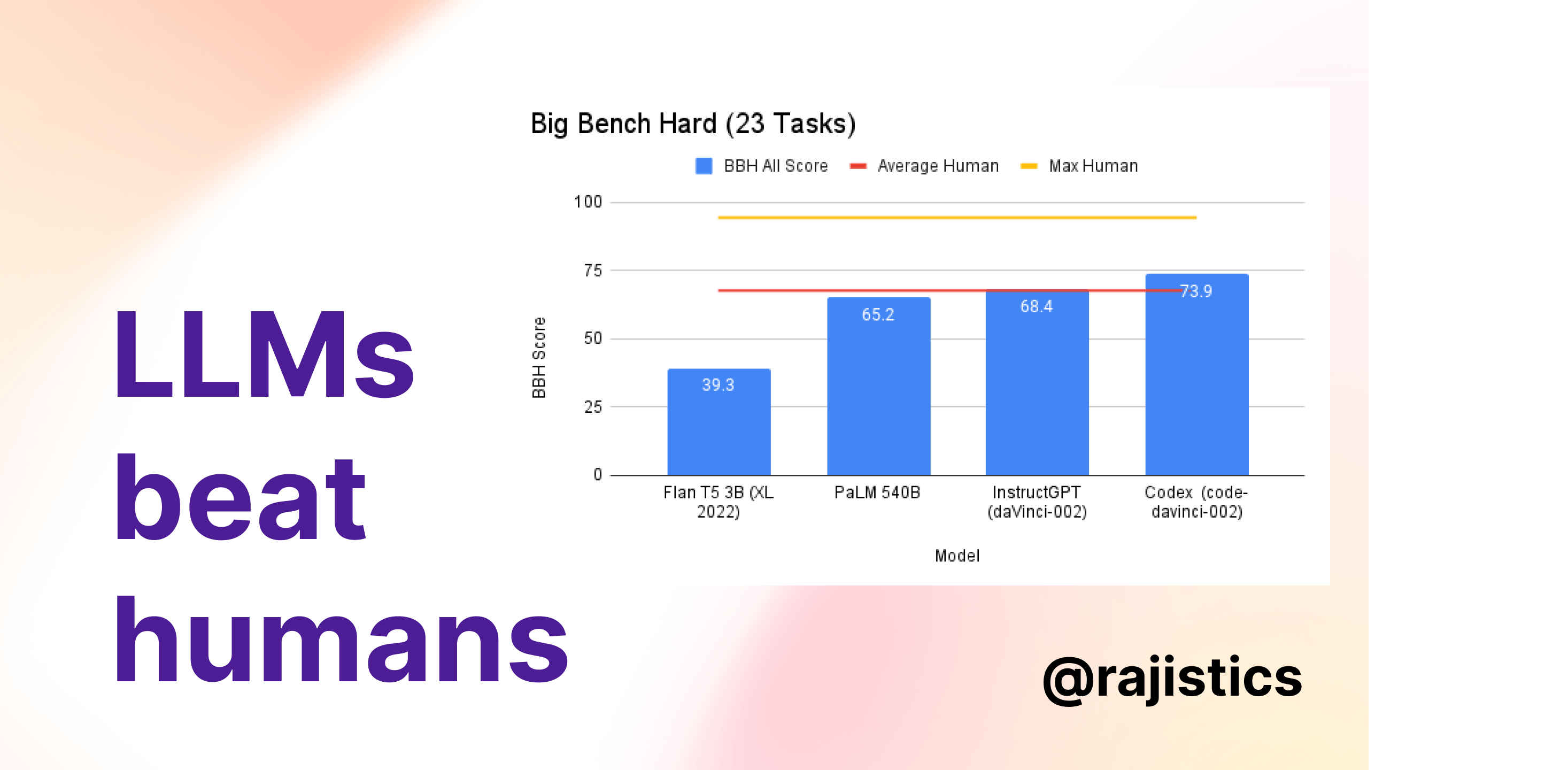
I came upon the Big Bench Benchmark, composed of more than 200 reasoning tasks. The tasks include playing chess, describing code, guessing the perpetrator of a crime in a short story, identifying sarcasm, and even recognizing self-awareness. A common benchmark to test models is the Big Bench Hard (BBH), a subset of 23 tasks from Big Bench. Early models like OpenAI’s text-ada-00 struggle to reach a random score of 25. However, several newer models reach and surpass the average human rater score of 67.7. You can see results for these models in these publications: 1, 2, and 3.
A survey of the research pointed out some common starting points for evaluating reasoning in models, including Arithmetic Reasoning, Symbolic Reasoning, and Commonsense Reasoning. This blog post provides examples of reasoning, but you should try out all these examples yourself. Hugging Face has a space where you can try to test a Flan T5 model yourself.
Arithmetic Reasoning
Let’s start with the following problem.
Q: If there are 3 cars in the parking lot and 2 more cars arrive, how many cars are in the parking lot?
A: The answer is 5If you ask an older text generation model like GPT-2 to complete this, it doesn’t understand the question and instead continues to write a story like this.

While I don’t have access to PalM - 540B parameter model in the Big Bench, I was able to work with the Flan-T5 XXL using this publicly available space. I entered the problem and got this answer!
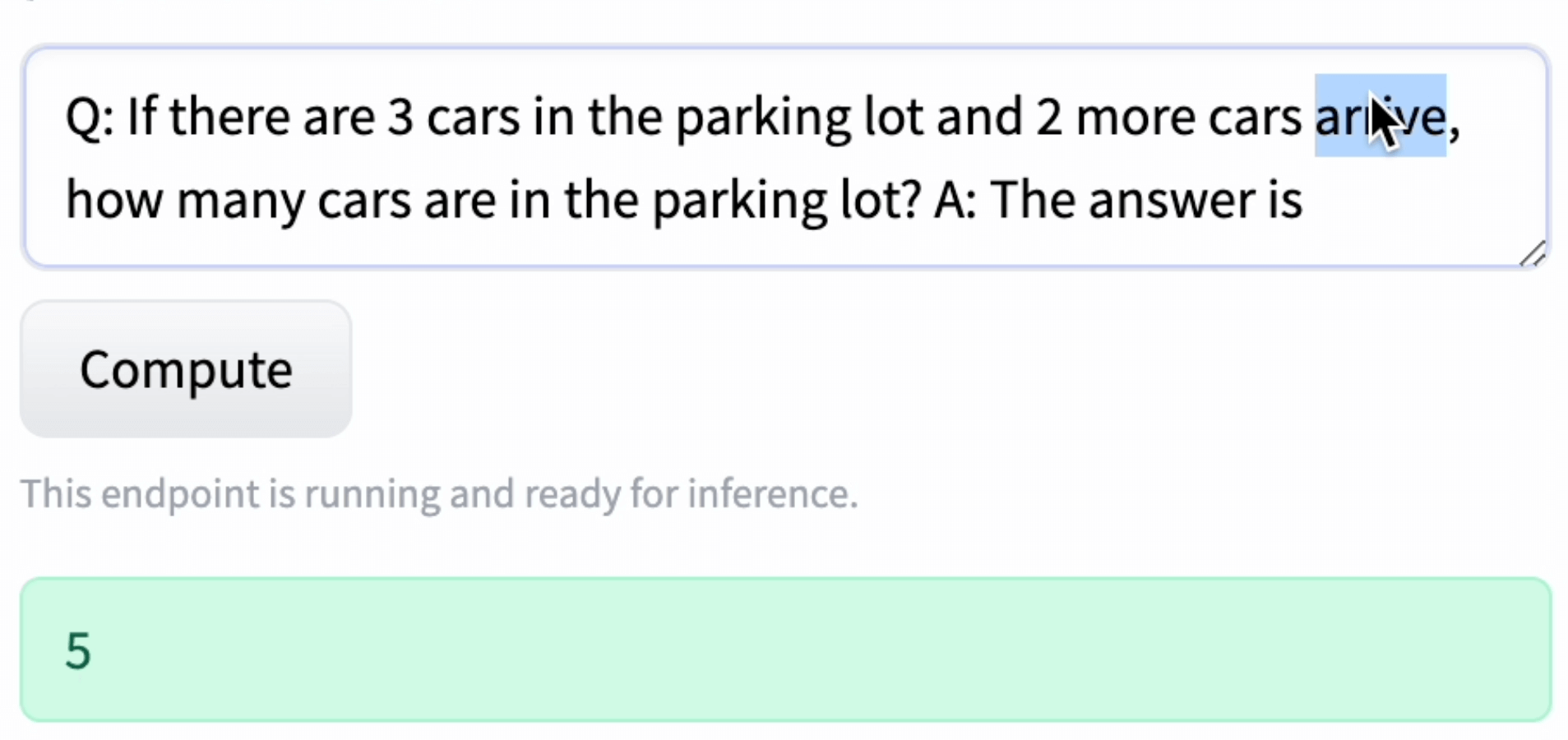
It solved it! I tried messing with it and changing the words, but it still answered correctly. To my untrained eye, it is trying to take the numbers and perform a calculation using the surrounding information. This is an elementary problem, but this is more sophisticated than the GPT-2 response. I next wanted to do a more challenging problem like this:
Q: A juggler can juggle 16 balls. Half of the balls are golf balls, and half of the golf balls are blue. How many blue golf balls are there?The model gave an answer of 8, which isn’t correct. Recent research has found using chain-of-thought prompting can improve the ability of models. This involves providing intermediate reasoning to help the model determine the answer.
Q: Roger has 5 tennis balls. He buys 2 more cans of tennis balls. Each can has 3 tennis balls. How many tennis balls does he have now?
A: Roger started with 5 balls. 2 cans of 3 tennis balls each is 6 tennis balls. 5 + 6 = 11. The answer is The model correctly answers 11. To solve the juggling problem, I used this chain-of-thought prompt as an example. Giving the model some examples is known as few-shot learning. The new combined prompt using chain-of-thought and few-shot learning is:
Q: Roger has 5 tennis balls. He buys 2 more cans of tennis balls. Each can has 3 tennis balls. How many tennis balls does he have now?
A: Roger started with 5 balls. 2 cans of 3 tennis balls each is 6 tennis balls. 5 + 6 = 11. The answer is 11.
Q: A juggler can juggle 16 balls. Half of the balls are golf balls, and half of the golf balls are blue. How many blue golf balls are there?
A:Try it, it works! Giving it an example and making it think everything through step by step was beneficial. This was fascinating for me. We don’t train the model in the sense of updating it’s weights. Instead, we are guiding it purely by the inference process.
Symbolic Reasoning
The first symbolic reasoning was doing a reversal and the Flan-T5 worked very well on this type of problem.
Reverse the sequence "glasses, pen, alarm, license".A more complex problem on coin flipping was more interesting for me.
Q: A coin is heads up. Tom does not flip the coin. Mike does not flip the coin. Is the coin still heads up?
A:For this one, I played around with different combinations of people flipping and showing the coin and the model, and it answered correctly. It was following the logic that was going through.
Common sense reasoning
The last category was common sense reasoning and much less obvious to me how models know how to solve these problems correctly.
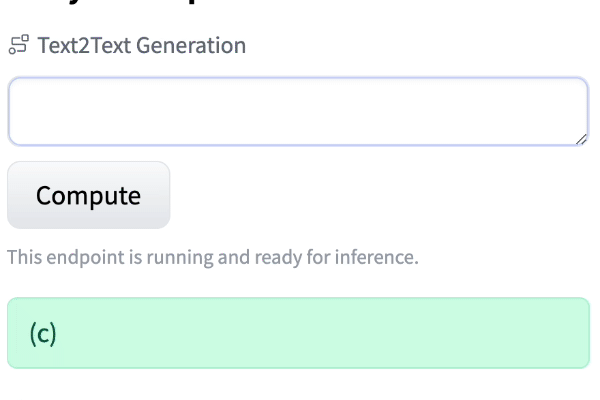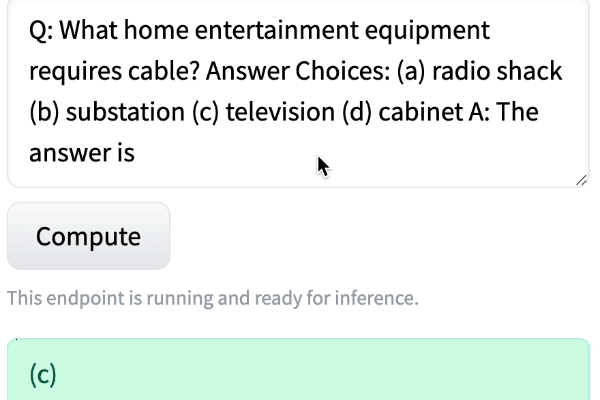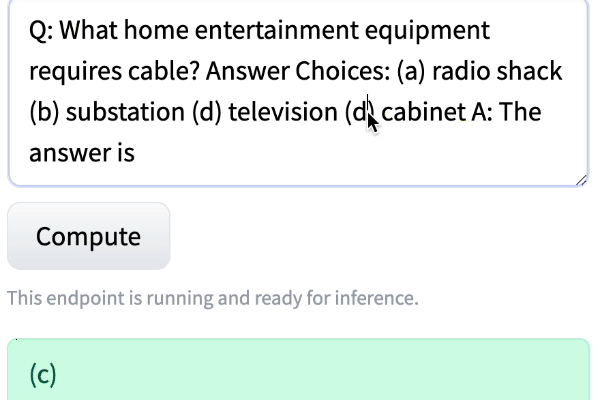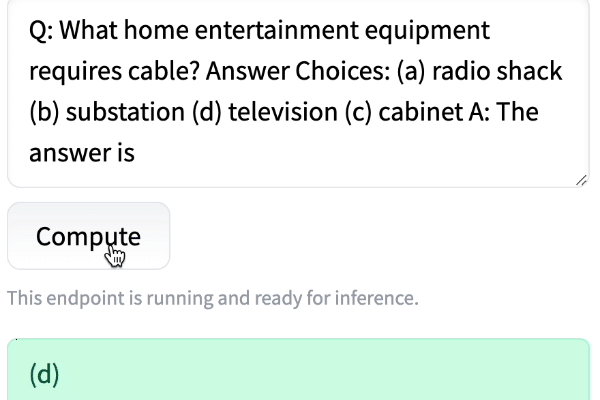
Q: What home entertainment equipment requires cable?
Answer Choices: (a) radio shack (b) substation (c) television (d) cabinet
A: The answer isI was amazed at how well the model did, even when I changed the order.
Another common reasoning example goes like this:
Q: Can Barack Obama have a conversation with George Washington? Give the rationale before answering.I changed around people to someone currently living, and it still works well.
Thoughts
As the first step, please, go try out these models for yourself. Google’s Flan-T5 is available with an Apache 2.0 license. Hugging Face has a space where you can try all these reasoning examples yourself. You can also replicate this using OpenAI’s GPT or other language models. I have a short video on the reasoning that also shows several examples.
The current language models have many known limitations. The next generation of models will likely be able to retrieve relevant information before answering. Additionally, language models will likely be able to delegate tasks to other services. You can see a demo of this integrating ChatGPT with Wolfram’s scientific API. By letting language models offload other tasks, the role of language models will emphasize communication and reasoning.
The current generation of models is starting to solve some reasoning tasks and match average human raters. It also appears that performance can still keep increasing. What happens when there are a set of reasoning tasks that computers are better than humans? While plenty of academic literature highlights the limitations, the overall trajectory is clear and has extraordinary implications.