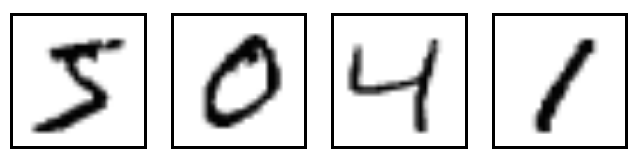
Introduction
For those running deep learning models, MNIST is ubiquotuous. This dataset of handwritten digits serves many purposes from benchmarking numerous algorithms (its referenced in thousands of papers) and as a visualization, its even more prevelant than Napoleon’s 1812 March. The digits look like this:
There are many reasons for its enduring use, but much of it is the lack of an alternative. In this post, I want to introduce an alternative, the Google QuickDraw dataset. The quickdraw dataset was captured in 2017 by Google’s drawing game, Quick, Draw!. The dataset consists of 50 million drawings across 345 categories. The drawings look like this:

Build your own Quickdraw dataset
I want to walk through how you can use this drawings and create your own MNIST like dataset. Google has made available 28x28 grayscale bitmap files of each drawing. These can serve as drop in replacements for the MNIST 28x28 grayscale bitmap images.
As a starting point, Google has graciously made the dataset publicly available with documentation on the dataset. All the data is sitting in Google’s Cloud Console, but for the images, you want this link of the numpy_bitmaps.
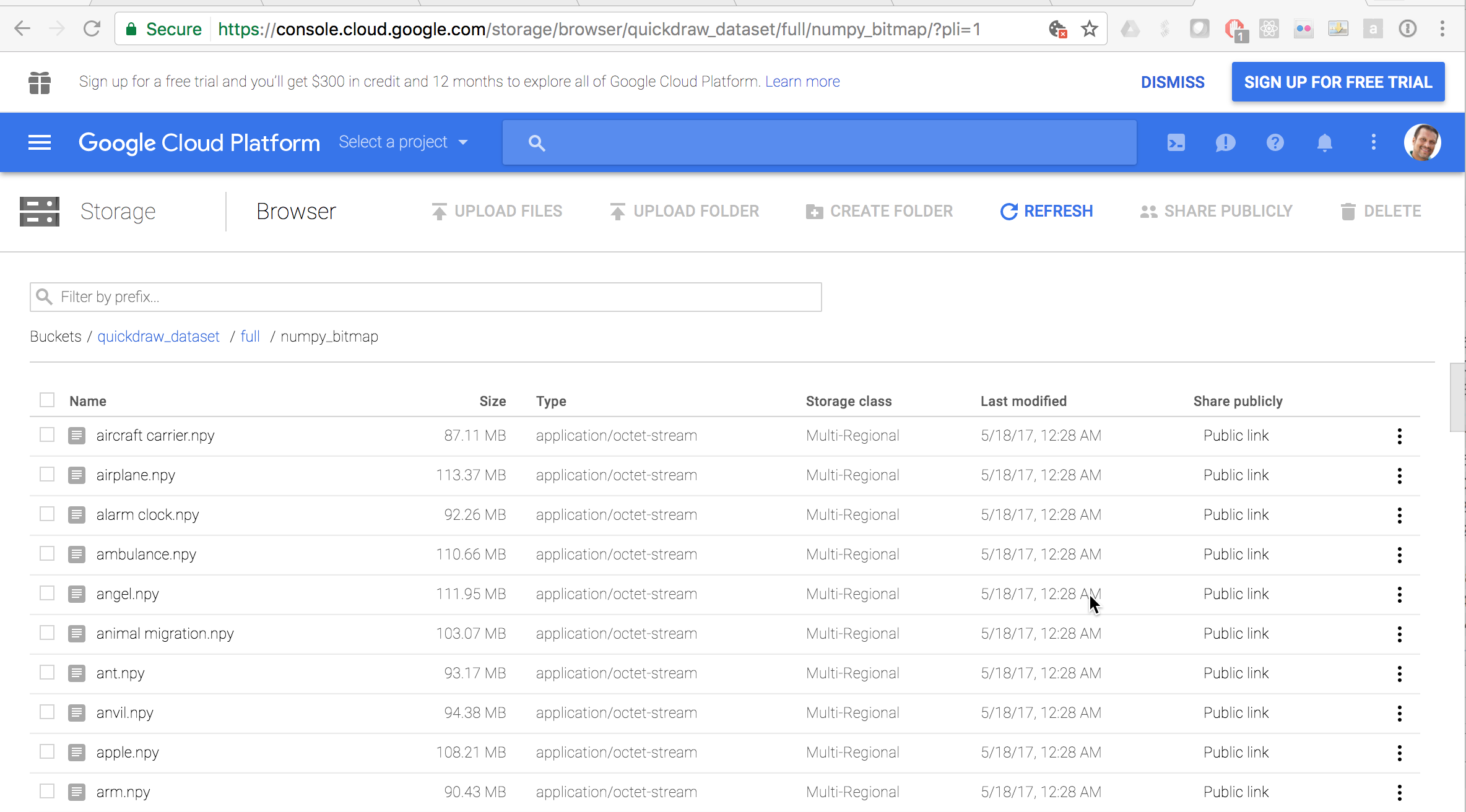
You should arrive on a page that allows you to download all the images for any category. So this is when you have fun! Go ahead and pick your own categories. I started with eyeglasses, face, pencil, and television. As I learned from the face, the drawings that have fine points can be more difficult to learn. But you should play around and pick fun categories.

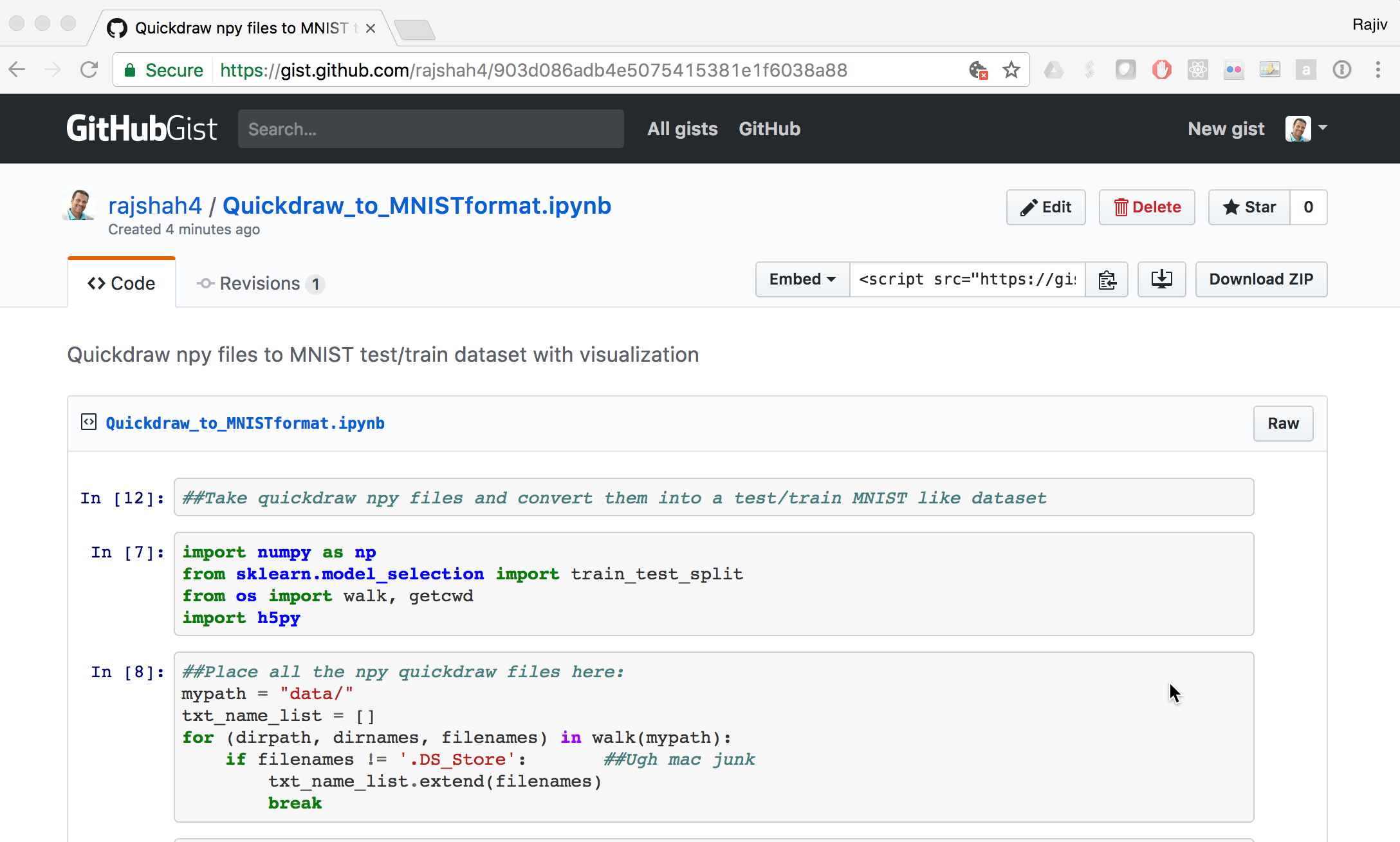
The next challenge is taking these .npy files and using them. Here is a short python gist that I used to read the .npy files and combine them to create a 80,000 images dataset that I could use in place of MNIST. They are saved in a hdf5 format that is cross platform and often used in deep learning.
Using Quickdraw instead of MNIST
The next thing is to go have fun with it. I used this dataset in place of MNIST for some work playing around with autoencoders in Python from the Keras tutorials. The below picture represents the original images at the top and reconstructed ones at the bottom, using an autoencoder.

I next used this dataset with a variational autoencoder in R. Here is the code snippet to import the data:
library(rhdf5)
x_test <- t(h5read("x_test.h5", "name-of-dataset"))
x_train <- t(h5read("x_train.h5", "name-of-dataset"))
y_test <- (h5read("y_test.h5", "name-of-dataset"))
y_train <- (h5read("y_train.h5", "name-of-dataset"))Here is a visualization of its latent space using my custom quickdraw dataset. For me, this was a nice fresh alternative to always staring at the MNIST dataset. So next time you see MNIST listed . . . go build your own!
